Versions of the library
ChASE is a modern C++ library for solving dense eigenvalue problems. The library provides multiple implementation variants to support different computing architectures and problem types. ChASE can be installed with minimal dependencies (BLAS, LAPACK) for sequential execution, or with MPI/ScaLAPACK for parallel execution on distributed systems. The library supports GPU acceleration on both NVIDIA and AMD platforms. On NVIDIA systems, ChASE uses CUDA, cuBLAS, and cuSOLVER, and supports distributed GPU execution via NCCL. On AMD/ROCm systems, ChASE uses HIP-based backends and supports distributed GPU communication through RCCL or MPI-based collectives.
Implementation Variants
ChASE provides four main implementation classes, each optimized for different computing environments:
Sequential Implementations
ChASECPU (
chase::Impl::ChASECPU): Sequential CPU implementation for single-node execution. This is the simplest configuration, suitable for single CPU systems or shared-memory multi-core systems. It uses BLAS and LAPACK for all numerical operations and supports both Hermitian and pseudo-Hermitian matrices.ChASEGPU (
chase::Impl::ChASEGPU): Sequential GPU implementation for single-GPU execution with GPU acceleration. Depending on the build backend, it uses CUDA libraries on NVIDIA systems or HIP libraries on AMD/ROCm systems. It supports both Hermitian and pseudo-Hermitian matrices.
Parallel Implementations
pChASECPU (
chase::Impl::pChASECPU): Parallel CPU implementation using MPI for distributed-memory systems. This configuration is best suited for multi-node CPU clusters. It supports block and block-cyclic matrix distribution schemes (Block, Block-Cyclic). Typically used with one MPI rank per NUMA domain and OpenMP threads for intra-node parallelism.pChASEGPU (
chase::Impl::pChASEGPU): Parallel GPU implementation for distributed-memory systems with GPU acceleration. Supported communication backends include MPI and NCCL on NVIDIA platforms, and MPI and RCCL on AMD/ROCm platforms. Current usage is one GPU per MPI rank. This configuration is suitable for heterogeneous multi-GPU clusters.
Matrix Types
ChASE supports two types of eigenvalue problems (Hermitian and Pseudo-Hermitian), each available in both sequential (non-distributed) and parallel (distributed) variants. The choice of matrix type depends on whether you are using sequential or parallel implementations.
Sequential (Non-Distributed) Matrix Types
These matrix types are used with sequential implementations (ChASECPU and ChASEGPU):
Hermitian (Symmetric) Matrices
Matrix Type:
chase::matrix::Matrix<T>(CPU) orchase::matrix::Matrix<T, chase::platform::GPU>(GPU)Problem Form: \(A \hat{x} = \lambda \hat{x}\) where \(A = A^*\)
Rayleigh-Ritz: Standard projection (NORMAL-RAYLEIGH-RITZ)
Orthonormalization: Standard QR factorization
Pseudo-Hermitian Matrices
Matrix Type:
chase::matrix::PseudoHermitianMatrix<T>(CPU) orchase::matrix::PseudoHermitianMatrix<T, chase::platform::GPU>(GPU)Problem Form: BSE Hamiltonian \(H\) satisfying \(SH = H^*S\)
Rayleigh-Ritz: Oblique projection with S-metric (OBLIQUE-RAYLEIGH-RITZ)
Orthonormalization: S-orthonormal QR factorization
Use Case: Bethe-Salpeter Equation (BSE) and similar applications
Parallel (Distributed) Matrix Types
These matrix types are used with parallel implementations (pChASECPU and pChASEGPU) and support different distribution schemes across MPI processes:
Hermitian (Symmetric) Matrices
Block Distribution:
chase::distMatrix::BlockBlockMatrix<T, Platform>Block-Cyclic Distribution:
chase::distMatrix::BlockCyclicMatrix<T, Platform>Redundant Distribution:
chase::distMatrix::RedundantMatrix<T, Platform>Problem Form: \(A \hat{x} = \lambda \hat{x}\) where \(A = A^*\)
Rayleigh-Ritz: Standard projection (NORMAL-RAYLEIGH-RITZ)
Orthonormalization: Standard QR factorization
Platform: Can be
chase::platform::CPUorchase::platform::GPU
Pseudo-Hermitian Matrices
Block Distribution:
chase::distMatrix::PseudoHermitianBlockBlockMatrix<T, Platform>Block-Cyclic Distribution:
chase::distMatrix::PseudoHermitianBlockCyclicMatrix<T, Platform>Problem Form: BSE Hamiltonian \(H\) satisfying \(SH = H^*S\)
Rayleigh-Ritz: Oblique projection with S-metric (OBLIQUE-RAYLEIGH-RITZ)
Orthonormalization: S-orthonormal QR factorization
Use Case: Bethe-Salpeter Equation (BSE) and similar applications
Platform: Can be
chase::platform::CPUorchase::platform::GPU
Matrix Distributions (Parallel Implementations)
For parallel implementations (pChASECPU and pChASEGPU), ChASE organizes MPI processes in a 2D grid and supports multiple data distribution schemes for assigning sub-blocks of the dense matrix to different MPI ranks.
Block Distribution
The Block Distribution (chase::distMatrix::BlockBlockMatrix) assigns
each MPI rank of the 2D grid a contiguous block of the dense matrix. This
distribution scheme is optimal for the Hermitian Matrix-Matrix Multiplication
kernel, which is the most computationally intensive operation in ChASE. The
block distribution results in large, contiguous matrix-matrix multiplications
on each node, often achieving performance close to the hardware theoretical peak.
Additionally, this data distribution allows efficient offloading of computations
to GPU accelerators.
The figure above shows an example of ChASE distributing a \(n \times n\) dense matrix \(A\) into a \(3 \times 3\) grid of MPI processes. In this example, the matrix \(A\) is split into a 2D grid of sub-matrices \(A_{i,j}\) where \(i \in [0,2]\) and \(j \in [0,2]\). Each sub-matrix \(A_{i,j}\) is assigned to the corresponding MPI rank in the 2D process grid.
Block-Cyclic Distribution
The Block-Cyclic Distribution (chase::distMatrix::BlockCyclicMatrix)
is a 2D block-cyclic distribution scheme originally introduced for dense matrix
computations on distributed-memory machines. Compared to the Block Distribution,
the main advantage of the Block-Cyclic Distribution is improved load balance
for matrix operations where the computational work varies across different
matrix entries, such as QR and LU factorizations.
Even though load balance is typically not a problem for ChASE (since the Hermitian Matrix-Matrix Multiplication kernel is well-balanced with Block Distribution), ChASE still provides the Block-Cyclic Distribution as an option to avoid data redistribution between different distribution schemes, which may be required for some applications, e.g., solving generalized eigenproblems with Cholesky factorization. In ChASE, the implementation with Block-Cyclic Distribution can achieve similar performance as the implementation with Block Distribution.
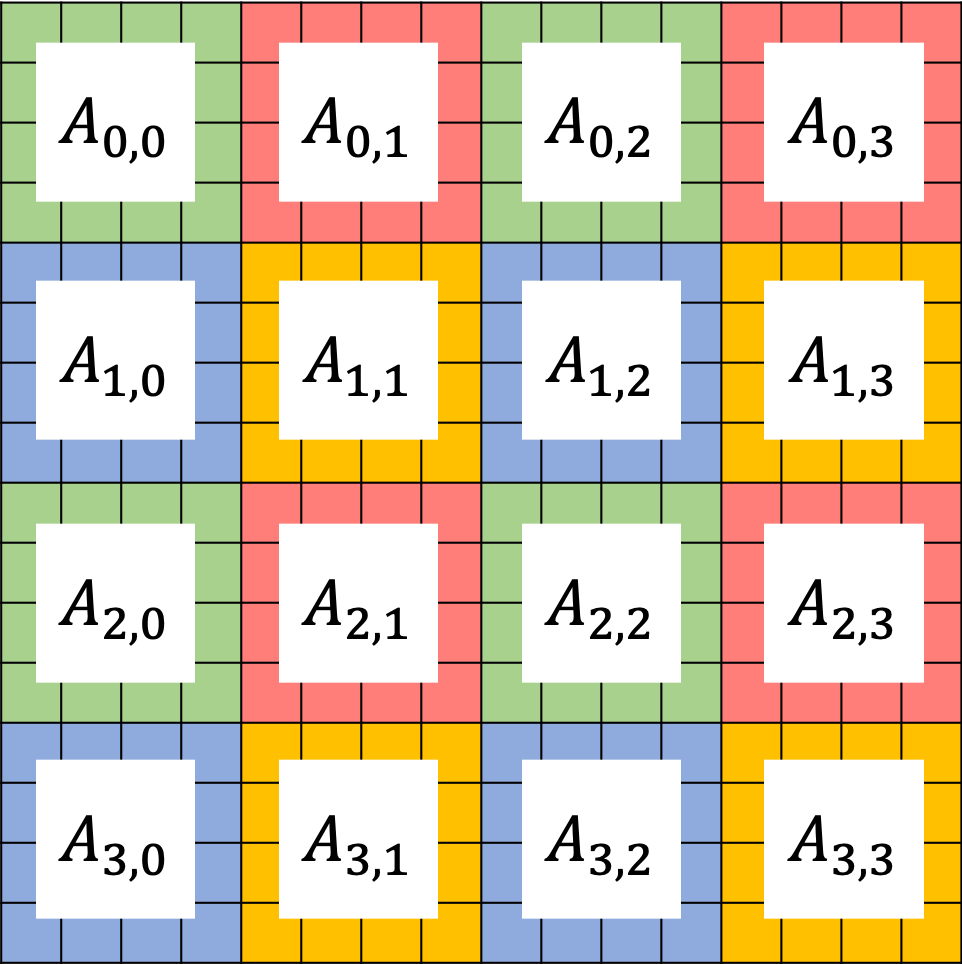
The figure above shows an example of ChASE distributing a \(n \times n\) dense matrix \(A\) into a \(2 \times 2\) grid of MPI processes in a block-cyclic scheme. Denoting the 4 MPI processes as \(P_{0,0}\), \(P_{0,1}\), \(P_{1,0}\), and \(P_{1,1}\), they are marked as green, red, blue and yellow, respectively in the figure above. In this example, the matrix \(A\) is split into a 2D grid of sub-matrices \(A_{i,j}\) where \(i \in [0,3]\) and \(j \in [0,3]\). Each sub-matrix is assigned to one MPI process in a round-robin manner so that each MPI rank receives several non-adjacent blocks, improving load balance for certain operations.
For more details about Block-Cyclic Distribution, please refer to the Netlib ScaLAPACK documentation.
Redundant Distribution
The Redundant Distribution (chase::distMatrix::RedundantMatrix) stores
a complete copy of the matrix on each MPI rank. This distribution is useful
for small to medium-sized matrices where communication overhead would be
prohibitive, or for operations that require global access to the matrix data.
Backend Communication
For parallel GPU implementations, ChASE supports multiple communication backends:
MPI Backend (
chase::grid::backend::MPI): Standard MPI communication, with support for CUDA-aware or HIP-aware MPI where available. This backend is suitable for systems with standard MPI installations and provides good inter-node communication performance.NCCL/RCCL Backend (
chase::grid::backend::NCCL): GPU collective communication backend. It maps to NCCL on NVIDIA platforms and RCCL on AMD/ROCm platforms when enabled in the build configuration.